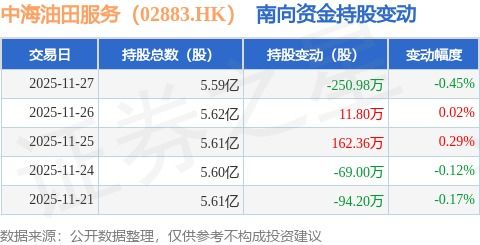
大數據時代的數據引擎 Hive數據倉庫與數據處理服務詳解

在當今數據驅動的商業與科研環境中,大數據技術已成為核心基礎設施。其中,Apache Hive作為一個構建在Hadoop之上的數據倉庫工具,以其強大的數據處理能力和相對友好的使用體驗,在企業級數據倉庫構建和數據分析領域占據了重要地位。本文將系統介紹Hive數據倉庫的核心概念、架構原理及其作為數據處理服務的關鍵角色。
一、Hive數據倉庫:定義與核心價值
Apache Hive是一個開源的數據倉庫框架,專為海量數據集(通常存儲在Hadoop分布式文件系統HDFS中)的查詢和管理而設計。其核心價值在于,它將復雜的MapReduce編程抽象化,允許用戶使用類似SQL的查詢語言(HiveQL或HQL)來處理數據,從而顯著降低了大數據處理的技術門檻。對于熟悉傳統關系型數據庫和SQL的數據分析師與工程師而言,Hive提供了一個平滑過渡到大數據生態的橋梁。
Hive并非一個傳統的在線事務處理(OLTP)數據庫,而是一個典型的批處理導向的在線分析處理(OLAP)系統。它更適合用于數據挖掘、離線分析、報表生成等場景,而非高并發的實時交易。
二、Hive的架構與工作原理
Hive的架構清晰地將用戶接口、元數據管理與查詢執行分離開來:
- 用戶接口:主要包括Hive命令行界面(CLI)、Web GUI(如Hue)以及通過JDBC/ODBC驅動連接的客戶端工具。用戶通過這些接口提交HiveQL查詢。
- 元數據存儲(Metastore):這是Hive的“大腦”,通常使用獨立的關系型數據庫(如MySQL、PostgreSQL)來存儲表結構、列類型、數據分區、文件路徑等元數據。元數據與數據的物理存儲分離,使得數據定義更加靈活。
- ?查詢編譯器與執行引擎:當用戶提交一條HQL語句后,Hive會對其進行解析、編譯、優化,并最終生成一個可在Hadoop集群上執行的MapReduce、Tez或Spark作業(具體取決于配置的執行引擎)。
- ?Hadoop核心:Hive本身不存儲數據,數據持久化在HDFS中。計算任務則由MapReduce、Tez或Spark等分布式計算框架執行,結果寫回HDFS或直接返回給用戶。
三、Hive作為數據處理服務的關鍵特性
- 表結構與數據模型:
- 內部表與外部表:內部表的數據生命周期由Hive管理,刪除表時會同時刪除HDFS上的數據;外部表僅管理元數據,刪除表不影響底層數據,常用于關聯已有數據文件。
- 分區與分桶:
- 分區:根據某一列(如日期
dt、地區region)的值將表數據物理分割到不同的HDFS目錄下。查詢時通過WHERE子句指定分區,可以避免全表掃描,極大提升查詢效率。
- 分桶:根據哈希函數將數據分散到固定數量的文件中,常用于提升采樣效率、優化特定類型的連接(JOIN)操作。
2. HiveQL:強大的查詢語言:
HiveQL不僅支持標準的SQL查詢(SELECT, JOIN, GROUP BY, ORDER BY等),還擴展了許多適合大數據場景的特性,如:
- 多表插入(Multi-Table Insert)、動態分區插入。
- 復雜的聚合函數、窗口函數(用于高級分析)。
- 用戶自定義函數(UDF)、用戶自定義聚合函數(UDAF)和用戶自定義表生成函數(UDTF),允許用戶用Java等語言擴展功能。
3. 多種文件格式與壓縮:
Hive支持多種高效的列式存儲格式,如ORC和Parquet。這些格式不僅壓縮率高,節省存儲空間,還支持謂詞下推、延遲物化等優化,能大幅提升查詢性能。配合Snappy、LZO等壓縮算法,可以在I/O和CPU開銷之間取得良好平衡。
4. 執行引擎的演進:
早期的Hive完全依賴MapReduce,延遲較高。現在,Hive支持將Tez或Spark作為執行引擎。Tez通過有向無環圖(DAG)優化任務執行,減少了中間結果的落盤開銷;Spark則利用內存計算,對于迭代式和交互式查詢性能提升顯著。這使Hive在保持批處理優勢的也能適應更快的查詢需求。
四、Hive在數據處理服務體系中的角色
在一個完整的企業級大數據平臺中,Hive通常扮演著核心數據倉庫和統一數據服務層的角色:
- 數據湖上的結構化視圖:原始數據(日志、事務記錄等)通過Flume、Sqoop、Kafka等工具攝入到HDFS或對象存儲(數據湖)中。Hive通過定義外部表,為這些半結構化/非結構化數據提供了一層結構化的元數據抽象,使其能夠被SQL便捷地訪問。
- ETL(抽取、轉換、加載)與數據加工:利用HiveQL強大的數據處理能力,可以編寫復雜的調度作業(通常由Azkaban、Oozie等調度工具協調),完成數據的清洗、轉換、聚合和維度建模,最終生成服務于不同業務線(如報表、用戶畫像、風險控制)的明細層、匯總層數據表。
- 即席查詢與交互式分析:數據科學家和業務分析師可以通過BI工具(如Tableau、Superset)連接Hive,對處理后的數據層進行自助式的探索和分析。
- 機器學習與數據科學的數據源:處理后的高質量數據可以方便地導出,或直接通過Spark SQL等接口,為Spark MLlib、TensorFlow等機器學習框架提供訓練和預測數據。
五、優勢、挑戰與未來展望
優勢:易用性高(SQL接口)、可擴展性強(依托Hadoop橫向擴展)、成本低廉(開源、可運行在廉價硬件上)、社區生態成熟。
挑戰:默認情況下查詢延遲較高(分鐘級),不適合極低延遲的實時場景;需要精細的調優(如分區設計、SQL寫法、參數配置)才能發揮最佳性能。
展望:隨著計算存儲分離架構、云原生數據倉庫(如Snowflake、BigQuery)的興起,Hive也在持續進化。例如,Hive on Spark、Hive LLAP(Live Long and Process)等項目旨在提供更快的交互式查詢體驗。Hive的元數據服務(Hive Metastore)已成為許多其他大數據組件(如Spark、Presto、Flink)的事實標準元數據目錄,其作為大數據生態“粘合劑”的角色愈發重要。
###
總而言之,Apache Hive作為大數據領域經典且強大的數據倉庫解決方案,通過將SQL的簡潔性與Hadoop生態的可擴展性相結合,成功構建了一個高效、穩定、易用的企業級數據處理服務平臺。盡管面臨實時化挑戰,但其在批處理、數據治理、大規模分析以及作為統一數據服務層方面的核心地位,在可預見的未來仍將不可替代。理解和掌握Hive,是深入大數據技術棧的關鍵一步。
如若轉載,請注明出處:http://m.i3130.cn/product/70.html
更新時間:2026-02-24 11:04:57